
[Data] 아파치 아이스버그 주요 개념 정리
아파치 아이스버그는 대규모 데이터 레이크에서 데이터를 효율적으로 관리하고 처리할 수 있도록 설계된 오픈 소스 테이블 포맷이다. 여기서 테이블 포맷은 일반적으로 데이터를 구조화하고 관리하는 방법을 뜻하는데 마치 DBMS에서 테이블 형태로 데이터를 저장하는 것처럼 분산 저장되어있는 파일들을 테이블 포맷으로 저장하고 관리할 수 있다.
주요 개념과 특징
- 테이블 포맷
- 아이스버그는 데이터 레이크에서 데이터를 테이블 포맷으로 관리한다. 기존의 데이터 레이크에서 사용하던 단순 디렉토리 구조나 파일 기반 접근 방식이 아니라 스키마와 메타데이터를 통해 데이터 제어 및 관리 기능을 제공한다.
- ACID 트랜잭션 지원
- 아이스버그는 분산 파일 시스템에서 ACID(Atomicity, Consistency, Isolation, Durability) 트랜잭션을 지원하여 데이터 레이크 환경에서 여러 사용자가 동시에 데이터를 읽고 쓸 때 데이터 일관성을 유지하는 역할을 한다.
- 버전 관리 지원
- 아이스버그는 데이터를 수정할 때마다 버전을 관리할 수 있다. 테이블의 스냅샷을 통해 이전 상태로 돌아가서 데이터를 분석하거나 데이터 변경 이력을 추적할 수 있기 때문에 유용하다.
- 파티셔닝 기능 지원
- 전체 데이터를 풀 스캔 하지 않고 파티션 기반으로 데이터를 효율적으로 쿼리하고 관리할 수 있는 기능을 제공한다.
- 히든 파티셔닝을 통해 날짜나 시간 기반의 복잡한 파티셔닝도 사용자가 쉽고 간단하게 구현할 수 있다.
아이스버그의 계층 구조
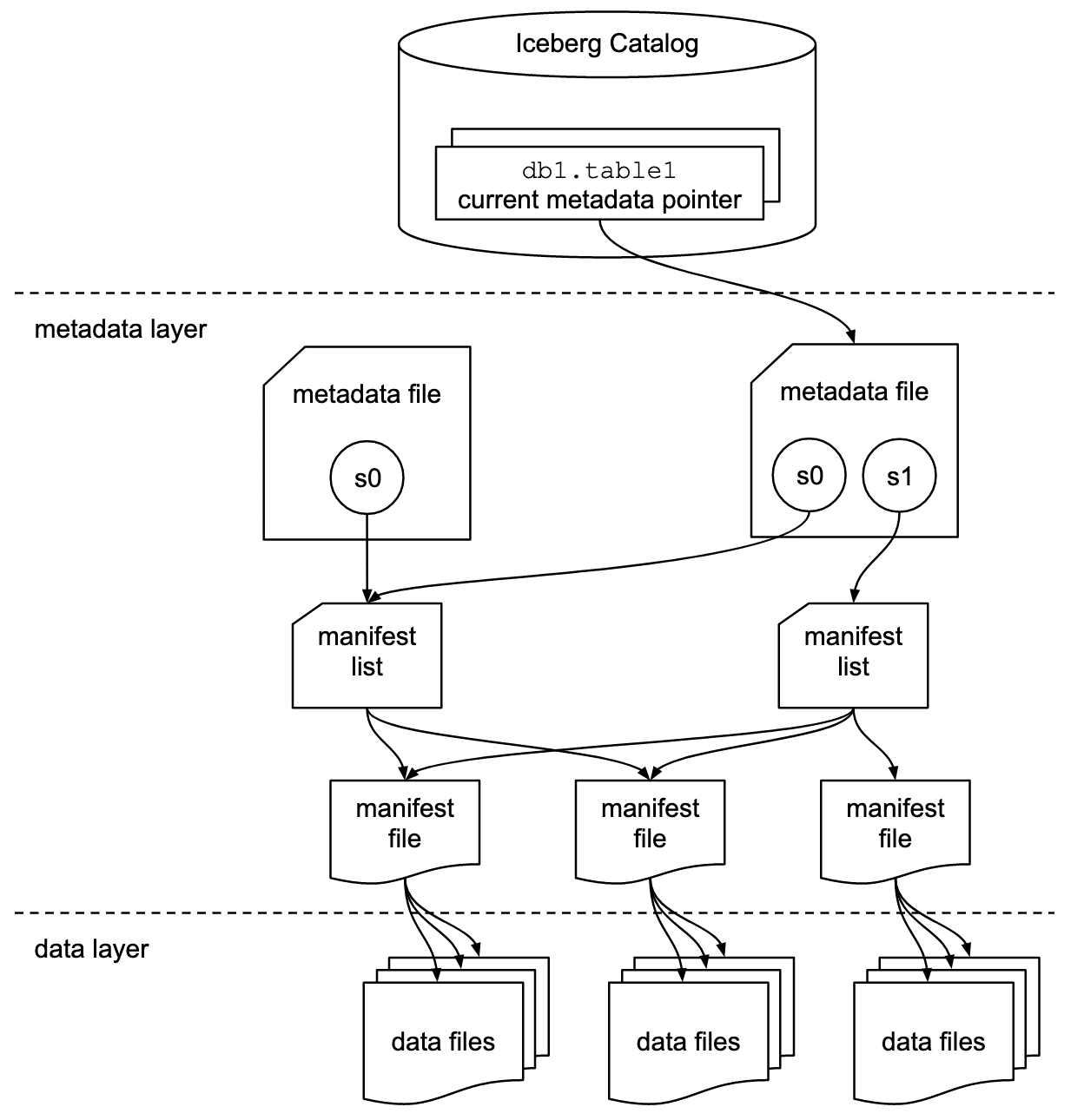
카탈로그
카탈로그는 테이블의 위치, 메타데이터, 스키마, 파티션 정보 등을 저장하고 관리하는 계층이다. 아이스버그 테이블을 식별하기 위해 현재 테이블을 정의하는 metadata.json의 위치를 엔진에게 제공하는 역할을 한다. 예를 들어 스파크 엔진을 사용한다고 하면 카탈로그가 스파크 세션에서 사용 가능한 테이블을 추적하여 작업할 수 있도록 하는 메커니즘을 제공한다. 스파크 엔진에서 사용 가능한 주요 카탈로그는 다음과 같다.
- Hadoop (File System)
- AWS Glue
- Project Nessie
- JDBC
- Hive
- DynamoDB
- REST Catalog
메타데이터 레이어
아이스버그는 데이터를 효율적으로 관리하고 빠르게 쿼리할 수 있도록 여러 메타데이터 파일을 사용한다. 메타데이터 파일은 각 목적에 따라 3가지로 나뉘는데 매니페스트 파일, 매니페스트 리스트, 메타데이터 파일이 있다.
메타데이터 레이어의 주요 요소
- 메타데이터 파일 (Metadata files) 메타데이터 파일은 테이블 전체를 정의하는 파일이다. 테이블의 구조와 상태를 포괄적으로 관리한다. 상세 기능으로는 테이블 정의, 스냅샷 관리, 매니페스트 리스트 추적 등이 있다.
- 매니페스트 리스트 (Manifest Lists) 매니페스트 리스트는 특정 스냅샷의 상태를 정의하는 파일로 스냅샷을 구성하는 모든 매니페스트 파일을 나열한다. 상세 기능으로는 스냅샷 구성 정의, 매니페스트 파일에 대한 추가적인 메타데이터 관리 등이 있다.
- 매니페스트 파일 (Manifest Files) 매니페스트 파일은 스냅샷의 서브셋으로 특정 시점의 테이블 상태를 나타낸다. 상세 기능으로는 개별 데이터 파일 추적, 데이터 파일에 대한 추가 메타데이터 관리 등이 있다.
데이터 레이어
데이터 레이어는 데이터를 실제로 저장하고 관리하는 부분으로 아이스버그 테이블의 핵심 요소이다. 데이터를 물리적으로 어떻게 저장하고 접근하는지에 대한 구체적은 방법을 다룬다. 데이터 레이어는 아이스버그 테이블이 저장된 파일과 해당 파일에 대한 메타데이터를 가지고 있고 대규모 데이터를 효율적으로 처리하도록 설계되어 있다.
데이터 레이어의 주요 요소
- 데이터 파일 (Data Files) 데이터 파일은 아이스버그 테이블의 가장 기본적인 요소로 실제 데이터가 저장된 파일을 뜻한다. 여러 포맷을 지원하며 일반적으로 Parquet, Avro, ORC 등의 포맷이 사용된다. 주로 컬럼 기반 파일 포맷을 사용하여 데이터 압축률이 좋기 때문에 대규모 데이터에서 좋은 성능을 제공한다. 저장 위치는 클라우드 스토리지(AWS S3, Azure Blob Stroage 등), 분산 파일 스토리지(HDFS 등), 로컬 시스템 등에 저장 된다.
- 파티션 (Partitions) 파티션은 데이터를 분할하는 방식이다. 쿼리 성능을 높이기 위해 파티션 컬럼을 기준으로 데이터를 그룹화 한다. DBMS에서 쿼리 성능을 향상 시키기 위해 인덱싱 전략을 고민한다면 아이스버그에서는 쿼리 성능 향상을 위해 파티셔닝 전략을 잘 짜야한다. 아이스버그의 파티셔닝 전략에 대해서는 추후 자세히 다룰 예정이다.
이번 아이스버그 글에서는 기본 개념과 주요 특징, 계층 구조에 대해서 다루었다. 아이스버그는 대규모 데이터 레이크에서 데이터를 효율적으로 관리하고 분석하는 도구로 데이터 레이크의 주요 시스템으로 자리매김하고 있다. 추후에는 아이스버그가 데이터를 읽고 쓰는 방식, ACID 트랜잭션을 사용하여 데이터의 일관성을 유지하는 방식, 버전 관리와 파티셔닝 전략 등을 자세히 살펴볼 예정이다.
Leave a comment